
Les LLM sont très efficaces par nature pour analyser et rédiger des textes. Maintenant ils deviennent très puissants pour faire des recherches approfondies, extraire et compiler des informations pertinentes a partir de plusieurs sources Internet et rédiger des rapports.
Mais comment faire pour utiliser cette puissance sur les données de l’entreprise ?
La plus grande partie des données en entreprise sont ce qu’on appelle des données non structurée par opposition aux données structurées généralement stocké dans des base de donnée dite SQL. Ces informations sont très riches et généralement très mal exploitée.
On parle par exemple, des emails clients ou fournisseurs, des tickets de support, des avis et réclamations des clients, réseaux sociaux, des rapports internes, des notes de réunion, des présentation ppt, des devis, factures et bons de commande, des documents RH, des retex collaborateurs, réclamation, des ordres d’achat, des inventaires, contenus marketing, contrats.
Grâce à l’IA générative, on peut maintenant plus facilement exploiter efficacement ces informations pour
- Mieux connaître ses clients et personnaliser l’offre,
- Capitaliser sur l’expérience et les savoirs de l’entreprise
- Accélérer la recherche et la prise de décision
- Améliorer la gestion administrative
- anticiper les problèmes à venir
Par exemple, il est possible de poser des questions en langage naturel comme :
- « Pouvez-vous analyser les tendances dans les retours clients sur les 6 derniers mois ? » En analysant les mails internes , les forums publique, les litiges, les remboursements”
- “Quels sont les problèmes internes récurrents mentionnés dans les rapports d’incidents techniques ?
- question rh collab, onboarding : ex comment gérer les congés exceptionnels
- « question capitaliser sur les savoir faires : «
- « une question signal faible récurrent »
- « Quels sont les derniers échanges avec [nom du client] sur le projet X ? »
Mette en oeuvre des premières solutions pour mieux exploiter toutes ces informations peut être très rapide. Toutes les tailles d’entreprises peuvent en bénéficier de la PME aux grands groupes.
Mais comment démarrer exploiter concrètement ses solutions ?
Chaque jour de nouveaux outils apparaissent toujours plus puissant, très différents et apparement très facile d’accès.
Mais comment identifier les produits vraiment pertinent ? Comment organiser leur intégrations dans l’entreprise de manière cohérente et sécurisé pour l’ensemble des collaborateurs ?
Certain outils sont cantonnés à des utilisations individuelles et gèrent très mal la sécurité. D’autres sont très complexe à appréhender pour commencer.
Des solutions sans programmation
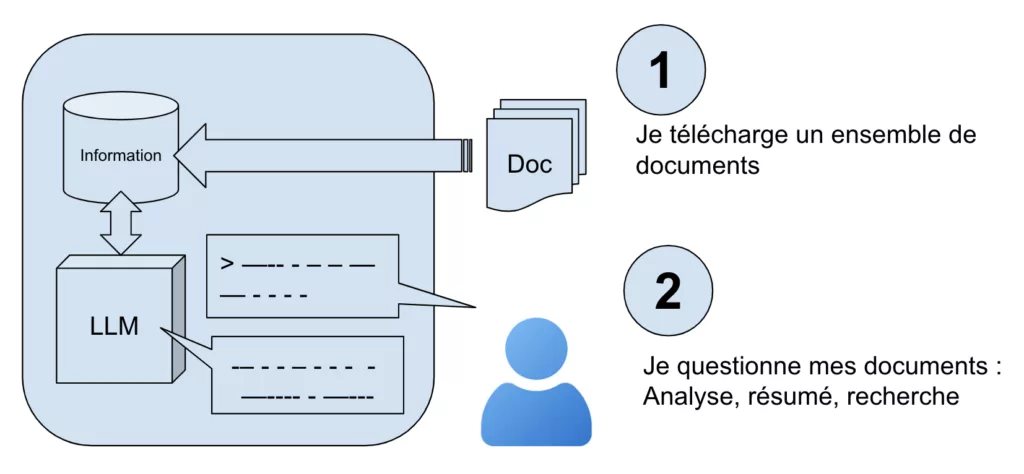
Les produits les plus efficace tout en restant simple sont par exemple NotebookLlm de Google ou ChatGpt Projects d’OpenAI.
Le principe est simple, il suffit dans un premier temps de télécharger ou téléverser un ou plusieurs documents, des pdf concernant les procédures RH de l’entreprise par exemples.
On peut ensuite de poser des questions en langage naturel sur les informations contenu dans ces documents. On peut demander, par exemple, « quelle est la procédure pour demander un congé exceptionnel? »
C’est une démarche individuelle qu’il faut relancer à chaque évolution des documents.
Des solutions d’automatisation plus techniques mais sans programmation
Pour des besoins récurrents, et plus complexe, il est possible d’automatiser les traitements.
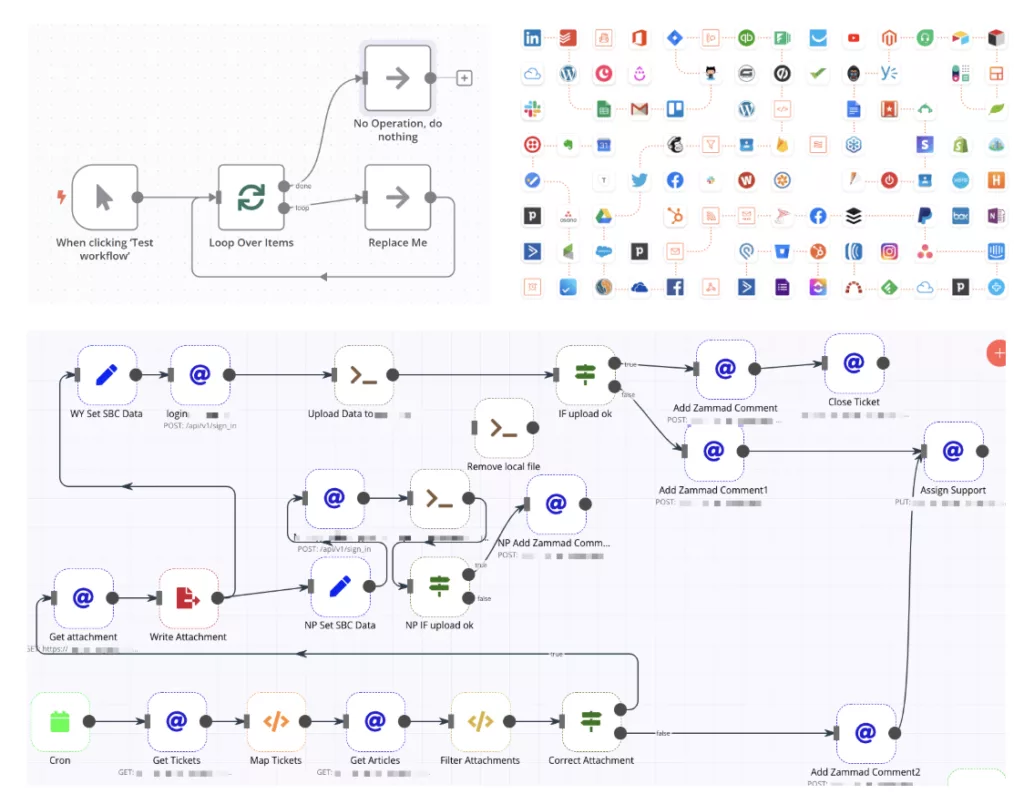
Les outils à envisager sont par exemple n8n, make, zapier …
Ils permettent , sans programmation, uniquement avec la souris, d’enchainer des appels d’outils déja existant dans l’entreprise accès au si. C’est des outils d’automatisation qui on intégrés les LLM.
On peut par exemple charger un ensemble de documents issue d’un répertoire google drive, les transformer pour les insérer dans une base sémantique. compléter par l’appel des documents de la semaine dans l’application de Support/CRM. puis lancer une analyse et la génération d’un rapport que l’on peut envoyer par mail à chaque responsables.
Pour les plus téméraires, les possibilités d’automatisation sont énormes.
La difficulté apparait quand les enchainements de traitement se complexifie. ça devient un plat de spaghetti.
Ces traitements sont aussi difficiles à maintenir et faire évoluer. La réutilisation à l’échelle de l’entreprise est difficile.
Des solutions spécialisées sur les LLM
Avec les LLM de nouveaux outils sont apparue pour manipuler le sens des phrases
Avec les LLM est arrivée une nouvelle possibilité pour capturer le sens des phrases et le traduire en représentation numérique (un vecteur).
On savait déjà vectoriser individuellement des mots mais sans tenir compte de leur position dans la phrase. L’arrivée des Transformers, qui à permis les LLM, a amené aussi la capacité à distinguer la position du mot dans la phrase lors de la vectorisation, c’est l’ »embeddings positionnels ».
On peut donc maintenant capturer le sens d’une phrase entière dans une représentation numérique et l’enregistrer dans une base de donnée.
On peut vectoriser un roman entier dans une base de donnée dite sémantique et retrouver, par exemple, tout les passages où le héros exprime des doutes.
C’est bien plus puissant que les solutions précédente qui ne permettaient de faire des recherche uniquement sur des suite de lettres, des mots clefs.
De nouvelles boites à outils sont alors apparue pour manipuler les LLM et les vecteurs, dans le cadre de manipulation de texte avec notament une architecture qui s’appelle RAG (Retrieval Augmented Generation).
Pour citer les outils les plus connu : LangChain et LlamaIndex.
On a donc deux approches pour travailler sur des documents non structurée en entreprise :
Choisir entre ces 2 approches très différentes
Certain traitements sont plus une intégration de LLM dans un enchainements d’outils reliés aux applications de l’entreprise (drive, base de données, gmail, calendrier) — > N8N, make …
ex de traitement orienté valorisation document non structuré
D’autres sont très centrée sur des traitements à base de recherche sémantique ou d’enchaiment de LLM avec des prompts complexes. –> LangChain et LlamaIndex.
Ex traitement orienté valorisation document non structuré
Des solutions robustes pour toute l’entreprise
Quand on passe de quelques applications développés par des utilisateurs avancé à des applications utilisables par l’ensemble des collaborateurs, il faut changer d’approche.
Des solutions adaptés à l’ensemble de l’entreprise doivent pouvoir proposer un ensemble de services minimum que l’on trouve plus difficilement dans les outils d’automatisation simples.
- la mutualisation des projets (réutilisation de sous ensembles de fonctions, gestion des versions)
- la garantie de performance en fonction du nombre d’utilisateur (scalabilité)
- la gestion centralisé de la sécurité (autorisation et contrôle des droits d’accès).
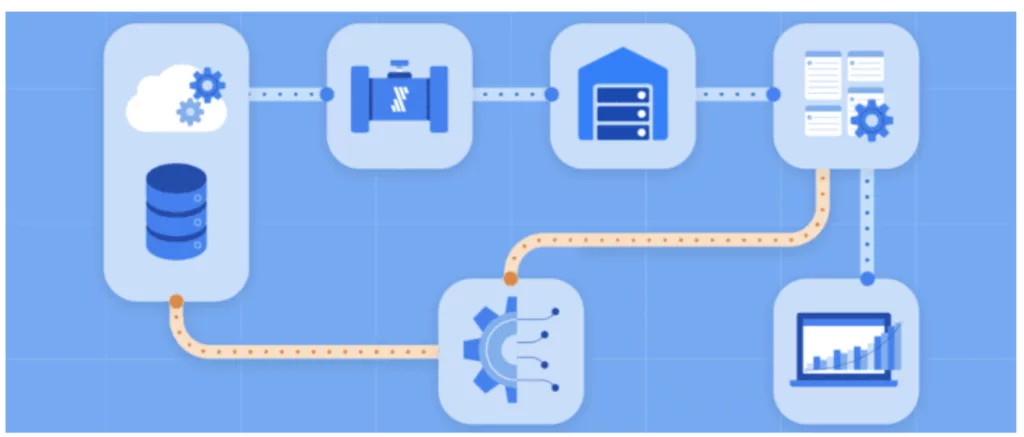
Le nombre ou la variété des documents à prendre en compte augmente, il faut concevoir une chaine d’ingestion documentaire dédié, avec par exemple de l’OCR et un stockage centralisé dans une base sémantique/vectorielle.
architecture RAG, avec agents
1 – Commencer par des solutions no-code qui savent évoluer
Google par exemple propose Vertex AI Agent Builder qui s’appuit sur toutes les briques habituelle de ses services cloud et une intégration maximum des fonctionnalités d’IA Générative.
En quelque click on peut construire une solution dite RAG (Retrieval Augmented Generation) : on sélectionne les documents concernés dans le cloud de l’entreprise et après quelques paramétrages rapides, on peut intégrer l’outils de question réponse dans des pages existante du site interne et tous les collaborateurs pourront questionner cette ensemble de documents.
Mais ici il est beaucoup plus facile d’enrichir l’application avec des fonctionnalité plus poussées.
2 – Ou investir sur du plus difficile a appréhender au départ mais 100% maitrisé
Langraph
puis pour garder la maitrise se construire une plateforme IA Gén avec : base de prompts, évaluation des performances, centralisation des liens avec les outils externes …
Voir l’article xxx.
Et la confidentialité ?
Lorsque l’on manipule des informations coeur de l’entreprise, la sécurité est cruciale.
Il est possible de construire des solutions 100% interne ou aucune information ne sort de l’entreprise (dont le LLM)
Mais le plus souple/agile/puissant est de s’appuyer sur des solutions SaaS qui savent s’adapter facilement au évolution et la variation de la charge.
Les solutions locales sont plus chers ?
partir sur des POC en SaaS pour valider les use cases puis construire la solution en production en local une fois le périmètre circonscrit.
A l’avenir, pour améliorer
Pour profiter au maximum des informations non structurer de l’entreprise, il faut porter une attention sur les DATA (exploitation temps réel, au fils de l’eau).
On peut aussi construire une synergie avec le SQL
une plateforme pour préparer l’arrivé des agents IA pour aller plus loin que la valorisation des données non structurée et aller vers l’automatisation des processus de l’entreprise.
Conclusion
Pour commencer à mieux exploiter vos document d’entreprise dès demain, contactez moi








